[版权申明]非商业目的注明出处可自由转载
出自:shusheng007
相关文章
Linux如何安装并配置Mariadb/Mysql
秒懂MySql之基础使用
前言
上一篇秒懂MySql之基础使用中谈论了mysql的一些基础使用知识,这篇谈论一下其稍微高级点的使用知识,包括分组、链接表、视图,存储过程、触发器,游标等。
随着移动互联网的发展,数据库早已进入分布式时代,所以使得这里的一些单机时代的产物渐渐失去了往日的荣光,例如:外键,表Join,存储过程,游标等大的互联网企业基本不用,不过某些特定场景下还是很有作用的,所以同学们各取所需吧。
分组数据(Group By)
- Group By
使用GROUP BY可以对数据进行分组汇总,分组的目的就是为了汇总。
因为你想啊,你都把数据按照某一列分组了,再查询其他列的数据意义也不大了,因为查出来的是每组中第一行的数据。
例如, 从products表中查询供应商id及商品价格并按照vend_id进行分组
SELECT vend_id,prod_price FROM products GROUP BY vend_id;输出:
+---------+------------+
| vend_id | prod_price |
+---------+------------+
| 1001 | 5.99 |
| 1002 | 3.42 |
| 1003 | 13.00 |
| 1005 | 35.00 |
+---------+------------+输出的商品价格是每一个供应商中的第一条商品数据的价格,意义不大。所以一般使用是使用分组和聚合函数来做统计。
例如统计一下每个供应商提供的商品个数以及商品平均价格
SELECT vend_id,AVG(prod_price) AS '平均价格',COUNT(*) AS '产品数目'
FROM products
GROUP BY vend_id;输出:
+---------+--------------+--------------+
| vend_id | 平均价格 | 产品数目 |
+---------+--------------+--------------+
| 1001 | 10.323333 | 3 |
| 1002 | 6.205000 | 2 |
| 1003 | 13.212857 | 7 |
| 1005 | 45.000000 | 2 |
+---------+--------------+--------------+注意,GROUP BY 后的列必须是查询的列。
- WITH ROLLUP
使用 WTIH ROLLUP 可以对分组后的聚合函数结果再一次聚合。
例如
SELECT vend_id,AVG(prod_price) AS avg_price,COUNT(*)
FROM products
GROUP BY vend_id
WITH ROLLUP;输出:
+---------+-----------+----------+
| vend_id | avg_price | COUNT(*) |
+---------+-----------+----------+
| 1001 | 10.323333 | 3 |
| 1002 | 6.205000 | 2 |
| 1003 | 13.212857 | 7 |
| 1005 | 45.000000 | 2 |
| NULL | 16.133571 | 14 |
+---------+-----------+----------+可以看到,最后一行的数据是对分组数据再一次使用了对应的聚合函数。
- HAVING
有时我们需要对分组后的数据进行过滤,例如上面我按不同的供应商统计了其提供的产品平均价格及种类,现在我们需要过滤出商品平均价格低于12块钱的供应商怎么办呢?这就用到了Having关键字。
SELECT vend_id,AVG(prod_price) AS '平均价格',COUNT(*) AS '产品种类'
FROM products
GROUP BY vend_id
HAVING AVG(prod_price)<12;输出:
+---------+--------------+--------------+
| vend_id | 平均价格 | 产品种类 |
+---------+--------------+--------------+
| 1001 | 10.323333 | 3 |
| 1002 | 6.205000 | 2 |
+---------+--------------+--------------+Having与Where关键字非常相似,唯一的区别就是Having 用在Group By 分组之后的组数据过滤。值得注意的是如果其条件中必须使用聚合函数表达式,不能用别名。
SQL子查询
这个其实也比较好理解,就是说Select查询出来的结果可以作为其他查询的一部分。
例如:
SELECT cust_name,
(SELECT COUNT(*)
FROM orders
WHERE orders.cust_id = customers.cust_id) AS orders
FROM customers
ORDER BY cust_name;输出:
+----------------+--------+
| cust_name | orders |
+----------------+--------+
| Coyote Inc. | 2 |
| E Fudd | 1 |
| Mouse House | 0 |
...
+----------------+--------+其中订单数目列是从orders表中查询出来的,我们可以嵌套任意多层子查询,子查询的执行顺序是由内到外的。
具体到上面的SQL的话就是:每一条数据都是先执行从orders表中查询出订单个数的sql,然后在执行外部的sql。
联接(Join)
由于MySql是关系型数据库,所以其表和表之间是存在紧密的关系的,所以往往需要检索多张表才能获得我们需要的数据。可以使用SQL的连接功能将多张表Join成一张表,从而获取数据。
值得注意的是,当前互联网行业中由于数据关系简单但易变,对并发及读写速度的超高需求,使得分库分表变的非常常见,而分库分表后数据库本身支持的一些功能就会丢失,例如外键,例如存储过程,例如表的Join。 所以如果大量使用Join的话,一旦分库分表后就需要重写,所以使得sql的可移植性降低,这使得互联网企业对程序员的sql水平要求反而降低了很多...
初识联接时感觉很复杂,后来发现有些根本就是理论,实际上都用不上。下面是网上流传的一张总结图片
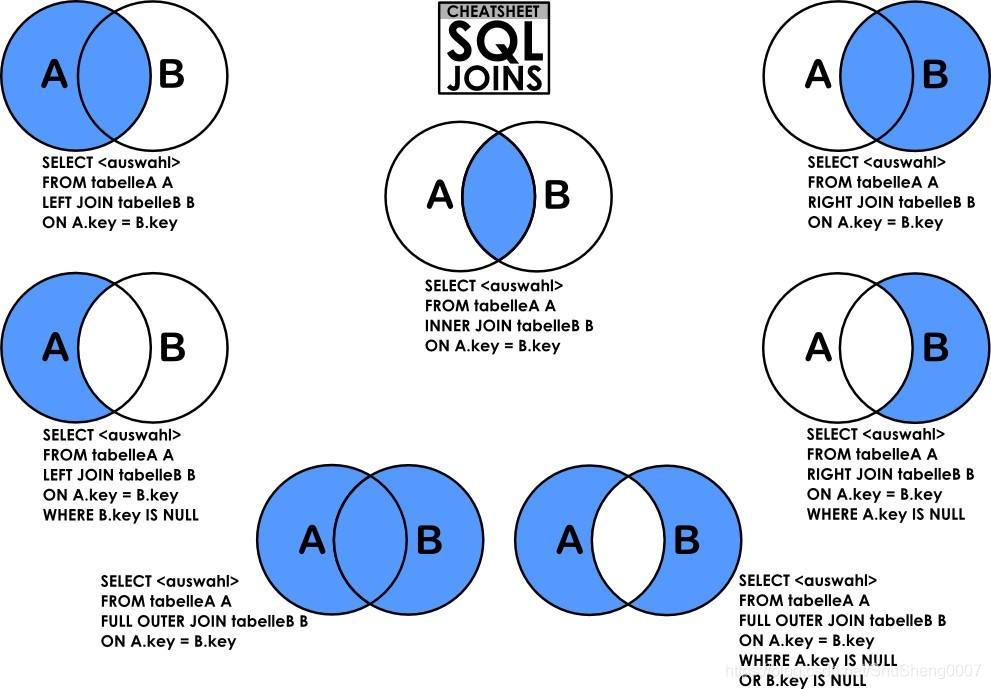
- 笛卡尔联接
直接From多张表即可,但是结果却是一张行数为多张表行数的乘积的表,例如连接两张表T1与T2的到一张T3的表,其中T1有1000行数据,T2有1000行数据,那么T3就拥有1000*1000=100000数据,两张1000行数据的表Join后变成了100万行的表,你说这玩意有啥用?所以笛卡尔连接基本没用!
SELECT T1.c1,T2.c2 FROM T1,T2;- 自然连接与内部联接
我们更多使用的是根据某一个条件进行联接的方式。
//条件联接
SELECT vendors.vend_id,vend_name,prod_name
FROM vendors, products
WHERE vendors.vend_id = products.vend_id ;
//内部联接
SELECT vendors.vend_id,vend_name,prod_name
FROM vendors INNER JOIN products
ON vendors.vend_id = products.vend_id ;上面两句sql的结果是一样的,执行过程也很好理解:两张表求交集。
+---------+-------------+----------------+
| vend_id | vend_name | prod_name |
+---------+-------------+----------------+
| 1001 | Anvils R Us | .5 ton anvil |
| 1001 | Anvils R Us | 1 ton anvil |
| 1001 | Anvils R Us | 2 ton anvil |
| 1002 | LT Supplies | Fuses |
| 1002 | LT Supplies | Oil can |
| 1003 | ACME | Detonator |
| 1003 | ACME | Bird seed |
| 1003 | ACME | Carrots |
| 1003 | ACME | Safe |
| 1003 | ACME | Sling |
| 1003 | ACME | TNT (1 stick) |
| 1003 | ACME | TNT (5 sticks) |
| 1005 | Jet Set | JetPack 1000 |
| 1005 | Jet Set | JetPack 2000 |
+---------+-------------+----------------+以程序员的语言来说就是两层嵌套for循环,只取相等的行
int count=0;
for(int i=0;i<t1.len;i++){
for(int j=0;j<t2.len;j++){
if(t1[i]==t2[j]){
t3[count++]= t1[i];
}
}
}值得注意的是,可以联接多张表,但是联接的表越多性能越低。
SELECT c1,c2...
FROM t1
INNER JOIN t2 ON join_condition1
INNER JOIN t3 ON join_condition2
...
WHERE where_conditions;- 外部联接
MySql 支持LEFT OUTER JOIN (与LEFT JOIN等价),RIGHT OUTER JOIN(与RIGHT JOIN等价),LEFT JOIN 表示左边的表的行都会得到保留,外加上左右表中都包含的行。
SELECT vendors.vend_id,vend_name,prod_name
FROM vendors LEFT OUTER JOIN products
ON vendors.vend_id = products.vend_id;输出为:
+---------+----------------+----------------+
| vend_id | vend_name | prod_name |
+---------+----------------+----------------+
| 1001 | Anvils R Us | .5 ton anvil |
| 1001 | Anvils R Us | 1 ton anvil |
| 1001 | Anvils R Us | 2 ton anvil |
| 1002 | LT Supplies | Fuses |
| 1002 | LT Supplies | Oil can |
| 1003 | ACME | Detonator |
| 1003 | ACME | Bird seed |
| 1003 | ACME | Carrots |
| 1003 | ACME | Safe |
| 1003 | ACME | Sling |
| 1003 | ACME | TNT (1 stick) |
| 1003 | ACME | TNT (5 sticks) |
| 1004 | Furball Inc. | NULL |
| 1005 | Jet Set | JetPack 1000 |
| 1005 | Jet Set | JetPack 2000 |
| 1006 | Jouets Et Ours | NULL |
+---------+----------------+----------------+对比INNER JOIN与LEFT OUTER JOIN的结果可以发现多了如下两行:
| 1004 | Furball Inc. | NULL |
| 1006 | Jouets Et Ours | NULL |这两行正是vendors表中存在而products表中不存在的记录。
组合查询(Union)
使用Union关键字可以将多条结构相同的SQL返回的结果组合起来。
什么叫结构相同呢?
- 多条查询SQL必须包含相同的列,聚合函数或者算术表达式。
- 这些列的数据类型必须兼容,即mysql可以帮助你隐式转换。
下面查询产品价格低于3块或者1002供应商的商品。
SELECT vend_id,prod_price
FROM products WHERE prod_price<3
UNION
SELECT vend_id,prod_price
FROM products WHERE vend_id =1002;输出:
+---------+------------+
| vend_id | prod_price |
+---------+------------+
| 1003 | 2.50 |
| 1002 | 3.42 |
| 1002 | 8.99 |
+---------+------------+值得注意的是UNION默认会剔除多条结果中相同的数据行,如果你要保留这需要使用UNION ALL。
MySql不支持FULL OUTER JOIN 但我们可以使用LEFT OUTER JOIN UNION RIGHT OUT JOIN来实现。
表(Table)
- 创建表
CREATE TABLE `user` (
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT 'id,主键',
`name` varchar(125) DEFAULT ' ' COMMENT '姓名',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;关于创建表这方面只想谈论一下那个ENGINE=InnoDB,这句话表示user表使用InnoDB数据库引擎。那么什么是数据库引擎呢?
数据库存储引擎是数据库底层软件。数据库管理系统(DBMS)使用数据引擎进行创建、查询、更新和删除数据。不同的存储引擎提供不同的存储机制、索引技巧、锁定水平等功能,使用不同的存储引擎,还可以 获得特定的功能。MySQL的核心就是存储引擎,支持多种不同的数据引擎。
我们可以使用SHOW ENGINES; 来查看你的MySql支持哪些数据库引擎。下面是我机器上的显示:
+--------------------+---------+--------------------------------------------------------------------------------------------------+--------------+------+------------+
| Engine | Support | Comment | Transactions | XA | Savepoints |
+--------------------+---------+--------------------------------------------------------------------------------------------------+--------------+------+------------+
| MRG_MyISAM | YES | Collection of identical MyISAM tables | NO | NO | NO |
| CSV | YES | Stores tables as CSV files | NO | NO | NO |
| MEMORY | YES | Hash based, stored in memory, useful for temporary tables | NO | NO | NO |
| MyISAM | YES | Non-transactional engine with good performance and small data footprint | NO | NO | NO |
| SEQUENCE | YES | Generated tables filled with sequential values | YES | NO | YES |
| Aria | YES | Crash-safe tables with MyISAM heritage | NO | NO | NO |
| PERFORMANCE_SCHEMA | YES | Performance Schema | NO | NO | NO |
| InnoDB | DEFAULT | Percona-XtraDB, Supports transactions, row-level locking, foreign keys and encryption for tables | YES | YES | YES |
+--------------------+---------+--------------------------------------------------------------------------------------------------+--------------+------+------------+那么为什么需要这么多数据库引擎呢?因为每个数据库引擎都有自己独特的能力,在某些特殊的场景下更高效,如果真出现一个打遍天下无敌手的数据库引擎的话,也就不需要这么多了。MySql默认引擎一般是InnoDB.
- 更新表
增加列
ALTER TABLE table ADD column ;删除列
ALTER TABLE table DROP column ;修改列
ALTER TABLE table MODIFY column ;- 删除表
DROP TABLE table;- 重命名
RENAME TABLE table1 TO table2;视图(View)
视图是什么?视图解决什么问题?如何创建?如何使用?
视图又称虚拟表,是映射真实表的一种设施。简单理解就是一堆写好的SQL查询语句,它代表的就是那条SQL语句查询出来的数据表。
例如有如下复杂的SQL语句,查询购买产品型号为TNT2的客户的信息
SELECT cust_name,cust_contact
FROM customers,orders,orderitems
WHERE customers.cust_id=orders.cust_id
AND orderitems.order_num= orders.order_num
AND orderitems.prod_id='TNT2';输出结果
+----------------+--------------+
| cust_name | cust_contact |
+----------------+--------------+
| Coyote Inc. | Y Lee |
| Yosemite Place | Y Sam |
+----------------+--------------+如果我们可以将上面的结果看成视图customerContact的话,就可以直接使用如下简单的查询完成上面那么复杂的功能
SELECT * FROM customerContact;你是不是已经对视图有了一个直观的印象了,那视图能带给我们哪些好处呢?
- 重用和简化SQL语句,就像上面的例子一样
- 安全性,你可以正对性的开放某些表的某些列的查询权限,而不是整个表
- 可以更改查询数据的格式
- 其他我不知道的。。。
要记住,视图主要目的是用来查询数据的!更新视图会有很多限制,因为更新了视图就意味着其映射的那些表也被修改了。只有简单sql生成的视图可以更新,复杂视图基本不能更新。
- 创建
CREATE VIEW customerContact AS
SELECT cust_name,cust_contact ,prod_id
FROM customers,orders,orderitems
WHERE customers.cust_id = orders.cust_id
AND orderitems.order_num = orders.order_num ;创建视图customerContact 后,要查询某一产品购买者的信息就非常简单了。
SELECT * FROM customerContact WHERE prod_id='TNT2';查询结果为:
+----------------+--------------+---------+
| cust_name | cust_contact | prod_id |
+----------------+--------------+---------+
| Coyote Inc. | Y Lee | TNT2 |
| Yosemite Place | Y Sam | TNT2 |
+----------------+--------------+---------+- 删除
DROP VIEW viewName;-更新
CREATE OR REPLACE VIEW viewName;存储过程(Procedure)
存储过程是什么?存储过程解决什么问题?有什么优缺点?如何创建?如何使用?
存储过程是一组为了完成某项特定功能的sql语句集,其实质是一段存储在数据库中的代码。简单来说存储过程是数据库 SQL 语言层面的代码封装与重用的一种方案。
单机时代时,使用存储过程不但可以封装数据业务逻辑,还可以提高执行效率,因为存储过程执行过一次后就会以二进制代码的形式缓存起来,下次执行的话就快了。但是进入分布式时代这些优点都消失了,反而多了很多缺点,因为存储过程是数据库相关的,移植性不强,oracle的存储过程在mysql上跑不了,甚至不同版本的mysql的存储过程都可能不能互相跑。还有调试困难,增加数据库服务器的压力。所以当今互联网时代,这个东西用的比较少了,这里只是简单介绍一下。
- 创建
CREATE PROCEDURE p_name(proc_parameter,...)下面是一个实例,根据是否需要课税来计算购买的商品总额。
DELIMITER &&
-- 名称: ordertotal
-- 参数:order_number
-- taxable 0 if not taxable, 1 if taxable
-- order_total
CREATE PROCEDURE ordertotal(
IN order_number INT,
IN taxable BOOLEAN,
OUT order_total DECIMAL(8,2)
)COMMENT '按照是否课税计算订单总额'
BEGIN
-- 声明变量
DECLARE total DECIMAL(8,2);
-- 声明税率
DECLARE taxrate INT DEFAULT 6;
-- 获取订单总额
SELECT Sum(item_price*quantity)
FROM orderitems
WHERE order_num = order_number
INTO total;
-- 是否需要课税
IF taxable THEN
SELECT total + (total/100*taxrate) INTO total;
END IF;
SELECT total INTO order_total;
END;
&&
DELIMITER ;如果要在mysql的命令行中运行此存储过程,需要暂时屏蔽;,使用DELIMITER && 通知mysql命令行程序暂时使用&&作为结束符,等待DELIMITER ;后换回;。
- 调用存储过程
CALL ordertotal(20005,1,@total);查看输出结果:
SELECT @total;
+--------+
| @total |
+--------+
| 158.86 |
+--------+- 删除
DROP PROCEDURE ordertotal;- 查看
- 查看存储过程状态
SHOW PROCEDURE STATUS LIKE 'ordertotal';结果:
+-----------+------------+-----------+----------------+---------------------+---------------------+---------------+--------------------------------------+----------------------+----------------------+--------------------+
| Db | Name | Type | Definer | Modified | Created | Security_type | Comment | character_set_client | collation_connection | Database Collation |
+-----------+------------+-----------+----------------+---------------------+---------------------+---------------+--------------------------------------+----------------------+----------------------+--------------------+
| learn_sql | ordertotal | PROCEDURE | root@localhost | 2020-12-28 16:33:32 | 2020-12-28 16:33:32 | DEFINER | 按照是否课税计算订单总额 | utf8mb4 | utf8mb4_general_ci | utf8mb4_general_ci |
+-----------+------------+-----------+----------------+---------------------+---------------------+---------------+--------------------------------------+----------------------+----------------------+--------------------+- 查看存储过程创建语句
SHOW CREATE PROCEDURE ordertotal;游标(Cursor)
什么是游标?解决什么问题?
游标是一个存储在MySql服务器上的数据库查询,是一个使用SQL语句检索出来的数据集。
使用游标可以迭代访问数据集中的每一条数据,MySql中的游标只能在存储过程中使用,就像在存储过程那部分谈到的,存储过程在分布式时代的重要性已经极大的下降了,所以连带游标的重要性也降低了不少。
- 创建
下面的语句创建了一个名为ordernumbers的游标,记住只能在存储过程中使用。
DECLARE ordernumbers CURSOR
FOR
SELECT order_num FROM orders;- 使用
第一步:打开游标
OPEN ordernumbers;第二步:读取游标
FETCH ordernumbers INTO 你定义的变量;这一步可以循环读取。
第三步:关闭游标
CLOSE ordernumbers;下面是一个完整的例子:
CREATE PROCEDURE processorders()
BEGIN
DECLARE done BOOLEAN DEFAULT 0;
DECLARE out INT;
-- 创建游标
DECLARE ordernumbers CURSOR
FOR
SELECT order_num FROM orders;
--声明一个Continue处理器,当游标读完数据后触发(SQLSTATE '02000' )
DECLARE CONTINUE HANDLER FOR SQLSTATE '02000' SET done=1;
--使用游标读取数据
OPEN ordernumbers;
-- 只是演示了利用游标不断读取数据的功能
REPEAT
FETCH ordernumbers INTO out;
UNTIL done END REPEATE;
CLOSE ordernumbers;
END; 触发器(trigger)
触发器是什么?解决什么问题?
触发器是一种和表关联的特殊的存储过程,可以在插入,删除或修改表中的数据时触发执行,比数据库本身标准的功能有更精细和更复杂的数据控制能力。
其可以解决的问题要基于其特性灵活应用,因为trigger可以在表插入、删除和修改表数据行的前后触发,所以我们就可以在这些地方做文章。例如在动作前可以拦截,在动作后可以记录等等。仍然是由于其是单机产物,在当前互联网时代作用下降,所以简单了解即可。
- 创建
-- 要是在mysql命令行执行要先执行这个
DELIMITER &&
CREATE TRIGGER trigger_deleteorder
BEFORE DELETE ON orders
FOR EACH ROW
BEGIN
INSERT INTO orders_deleted(order_num,order_date,cust_id)
VALUES(OLD.order_num,OLD.order_date,OLD.cust_id);
END;
&&
DELIMITER ;从orders表删除数据前orders_deleted的表是空的
SELECT * FROM orders_deleted;输出:
Empty set (0.00 sec)执行删除后发现orders_deleted表中插入了被删除的数据
DELETE FROM orders WHERE order_num=20005;
SELECT * FROM orders_deleted;输出:
+-----------+---------------------+---------+
| order_num | order_date | cust_id |
+-----------+---------------------+---------+
| 20005 | 2005-09-01 00:00:00 | 10001 |
+-----------+---------------------+---------+- 删除
DROP TRIGGER trigger_deleteorder;事务(Transaction)
事务应该是比较常用的概念了,但是也挺复杂的。一般来说,事务是必须满足4个条件(ACID):原子性(Atomicity,或称不可分割性)、一致性(Consistency)、隔离性(Isolation,又称独立性)、持久性(Durability)。
原子性:是指事务是一个最小单元,不可再分隔,成为一个整体。
一致性:是指事务中的方法要么同时成功,要么都不成功。比如A向B转账,要不都成功,要不都失败。
隔离性:数据库允许多个并发事务同时对某一记录进行读写和修改,隔离性可以防止多个事务并发执行时由于交叉执行而导致数据的不一致。事务隔离分为不同级别,包括读未提交(Read uncommitted)、读提交(read committed)、可重复读(repeatable read)和串行化(Serializable)。
持久性:事务处理结束后,对数据的修改就是永久的,即便系统故障也不会丢失。
单机时代,主流数据库都可以很好的支持事务,但是到了分布式时代就比较尴尬了。虽然后来发明了分布式事务,但是复杂而低效,业界大部分事务场景下使用最终一致性来解决。
MySql支持的那些数据库引擎好像使用InnoDB支持事务。
- 术语
事务(Transaction):指一组SQL语句
回滚(Rollback): 指撤销指定SQL语句的过程
提交(Commit): 指将未存储的SQL语句结果写入数据库表
保留单(Savepoint):指事务中设置的临时点,我可以回滚到这个点。
- 使用
一般的MySql语句都是隐含提交(implicit commit)的,即是自动提交的。而事务处理中是需要显式提交的。
启动事务
例如下面如果没有COMMIT 中间那些sql语句是不会执行的。
START TRANSACTION
....
....
COMMIT;回滚事务
START TRANSACTION
....
ROLLBACK;
....回滚到保留点
START TRANSACTION
....
SAVEPOINT sp1;
...
SAVEPOINT sp2;
...
ROLLBACK TO sp2;
....字符集(Character)与校对(Collate)
由于MySql数据库要存储全世界各种各样的语言,所以字符集非常重要,校对对数据排序很重要。
我们可以正对数据库服务器,数据库,表,列来设置字符集和校对。一般情况下我们字符集使用utf8mb4,校对使用utf8mb4_general_ci。utf8mb4 可以存放emoj表情,_ci 不区分大小写,_cs区分大小写
下面举个创建表时设置字符集和校对方式的例子
CREATE TABLE table(
c1 INT,
c2 VARCHAR(125) CHARACTER SET utf8 COLLATE utf8_general_ci
)DEFAULT CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci;权限管理
这个一般程序员用的少,DBA用的多。由于数据是敏感的,必须给使用者授予合适的权限,不然就是灾难。
管理用户
- 查看账户
Mysql 用户账号都是存储在一个叫mysql数据库的user表中。
查看MySql数据库的用户
USE mysql;
SELECT User,Host,Password FROM user;输出结果:
+-------+-----------+-------------------------------------------+
| User | Host | Password |
+-------+-----------+-------------------------------------------+
| root | localhost | *xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx |
| root | % | *xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx |
| admin | % | *xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx |
| admin | localhost | *xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx |
+-------+-----------+-------------------------------------------+- 增加用户
下面的sql创建一个名为ben的用户,其登录密码为123456
CREATE USER ben IDENTIFIED BY '123456';结果:
+-------+-----------+-------------------------------------------+
| User | Host | Password |
+-------+-----------+-------------------------------------------+
| ben | % | *6BB4837EB74329105EE4568DDA7DC67ED2CA2AD9 |
+-------+-----------+-------------------------------------------+- 重命名用户
RENAME USER ben TO ss007;结果:
+-------+-----------+-------------------------------------------+
| User | Host | Password |
+-------+-----------+-------------------------------------------+
| ss007 | % | *6BB4837EB74329105EE4568DDA7DC67ED2CA2AD9 |
+-------+-----------+-------------------------------------------+- 删除用户
DROP USER ss007;设置用户权限
必须给用户授予相关权限才能对数据进行操作。
我们先看一下刚刚增加的用户ss007都有什么权限。
SHOW GRANTS FOR ss007;结果:
+------------------------------------------------------------------------------------------------------+
| Grants for ss007@% |
+------------------------------------------------------------------------------------------------------+
| GRANT USAGE ON *.* TO 'ss007'@'%' IDENTIFIED BY PASSWORD '*6BB4837EB74329105EE4568DDA7DC67ED2CA2AD9' |
+------------------------------------------------------------------------------------------------------+可以发现ss007有一个USAGE ON *.*的权限,USAGE表示根本没有权限,所以此用户完全没有操作任何数据的权限。下面我们为其授予一定的权限。
- 给007授予learn_sql数据库所有表的查询权限
GRANT SELECT ON learn_sql.* TO ss007;输出
+------------------------------------------------------------------------------------------------------+
| Grants for ss007@% |
+------------------------------------------------------------------------------------------------------+
| GRANT USAGE ON *.* TO 'ss007'@'%' IDENTIFIED BY PASSWORD '*6BB4837EB74329105EE4568DDA7DC67ED2CA2AD9' |
| GRANT SELECT ON `learn_sql`.* TO 'ss007'@'%' |
+------------------------------------------------------------------------------------------------------+从SELECT ON learn_sql.*可见,ss007已经拥有了对learn_sql数据库所有表的SELECT权限。
我们再给其添加一个INSERT权限
GRANT INSERT ON learn_sql.* TO ss007;结果:
GRANT SELECT, INSERT ON `learn_sql`.* TO 'ss007'@'%' 可以发现多了INSERT权限。
- 撤销007对learn_sql所有表的Insert权限
REVOKE INSERT ON learn_sql.* FROM ss007;note: ss007 表示ss007@'%',%表示不限制链接数据库的机器,如果你想限制值只允许次用户从某个IP连接,就将%换成那个IP地址。如果限制只能从安装数据的机器上访问数据库,将%换成localhost即可。
授予(GRANT)与撤销(REVOKE)权限可以在以下粒度上进行
整个服务器:GRANT ALL 与REVOKE ALL
整个数据库:GRANT xxx ON database.*
特定表: GRANT xxx ON database.table
特定列: GRANT xxx(column) ON database.table
存储过程
总结
走马观花的谈论了一些MySql高级一点的话题,基本着眼于应用层面,都不深入。加上当今处于互联网时代,很多单机时代的数据库特性的重要性已经大不如前,没必要过于深入。本文作为参考书还是比较实用的,建议收藏,顺便点个赞也是要的...
元旦将近,2020年也要结束了,你年初的计划完成了吗?


文章评论